Melissa¶

Summary¶
Melissa is a file avoiding, fault tolerant and elastic framework, to run large scale sensitivity analysis and large scale deep surrogate training on supercomputers. Some of the largest Melissa studies so far employed up to 30k cores to execute 80 000 parallel simulations while avoiding up to 288 TB of intermediate data storage (see 1).
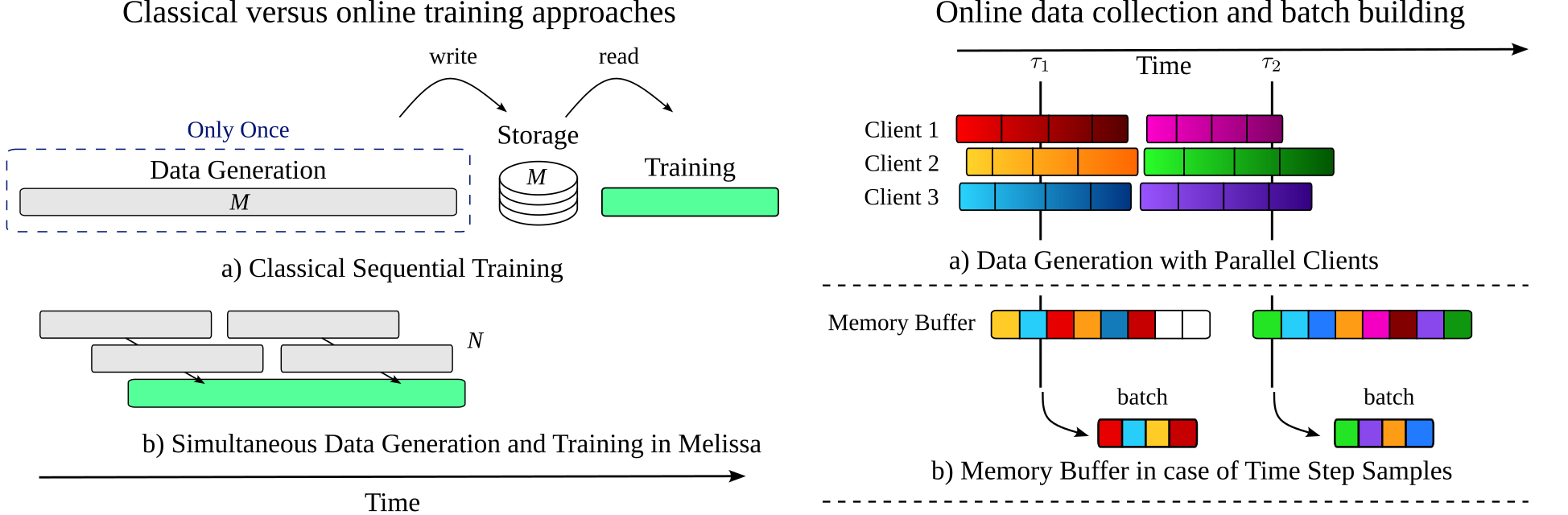
Classical sensitivity analysis and deep surrogate training consist in running different instances of a simulation with different set of input parameters, store the results to disk to later read them back to train a Neural Network or to compute the required statistics. The amount of storage needed can quickly become overwhelming, with the associated long read time that makes data processing time consuming. To avoid this pitfall, scientists reduce their study size by running low resolution simulations or down-sampling output data in space and time.
How it works¶
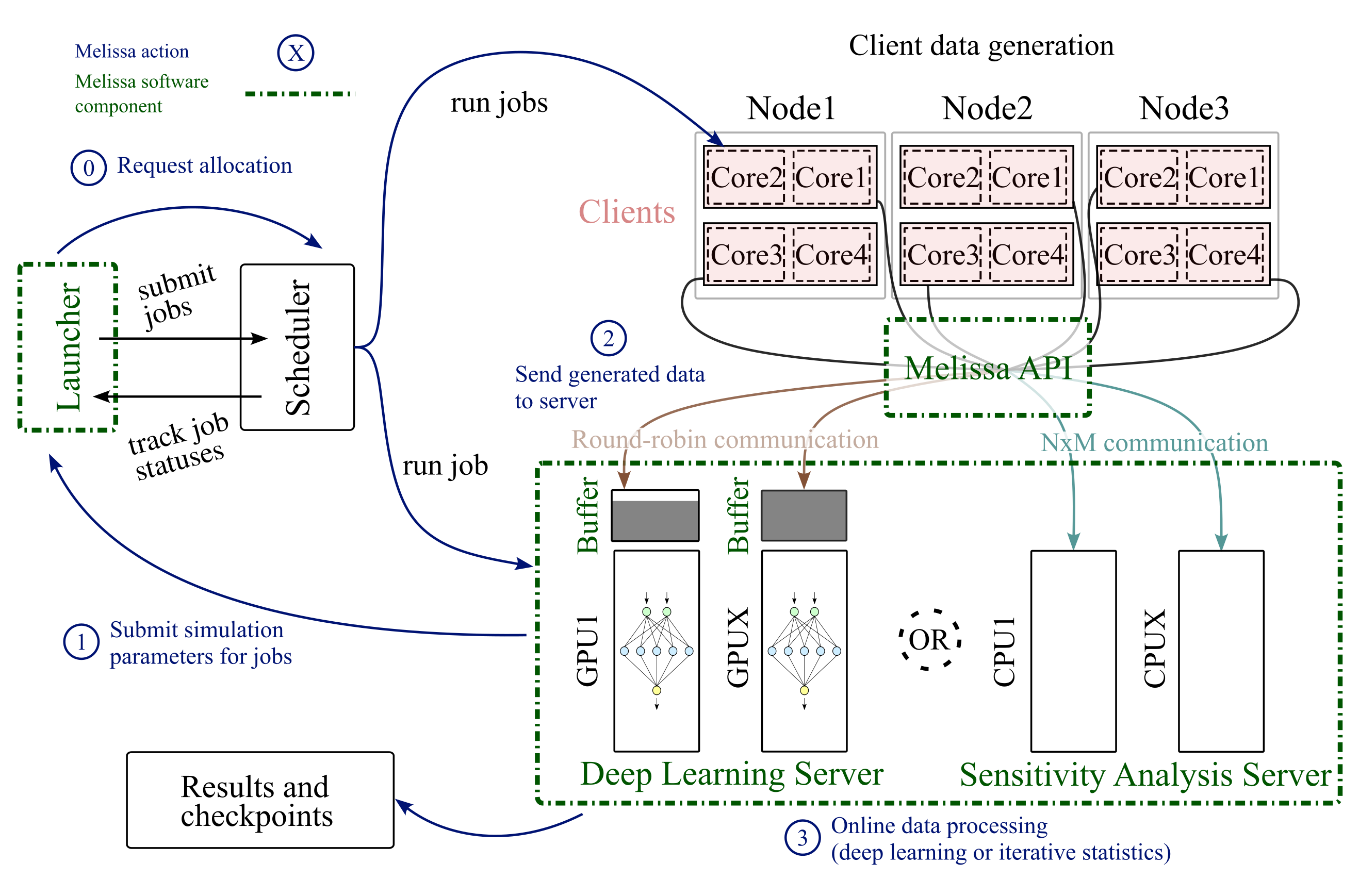
Melissa (Fig. 1) bypasses this limitation by avoiding intermediate file storage. Melissa processes the data online (in transit) enabling very large scale data processing:
-
Melissa's sensitivity analysis server is built around two key concepts: iterative (sometimes also called incremental) statistics algorithms and asynchronous client/server model for data transfer. Simulation outputs are never stored on disk. Instead, they are sent via NxM communication patterns from the simulations to a parallelized server. This method of data aggregation enables the calculation of rapid statistical fields in an iterative fashion, without storing any data to disk. This allows to compute oblivious statistical maps on every mesh element, for every time step and on a full scale study. Melissa comes with iterative algorithms for computing various statistical quantities (e.g. mean, variance, skewness, kurtosis and Sobol indices) and can easily be extended with new algorithms.
-
Melissa's deep learning server adopts a similar philosophy. Clients communicate data in a round-robin fashion to the parallelized server. The multi-threaded server then puts and pulls data samples in and out of a buffer which is used for building training batches. Hence as the amount of samples reaches a safety watermark (sometimes also referenced as threshold), they are selected to form batches used to perform data distributed training on GPUs or CPUs. To ensure a proper memory management during execution, samples are selected and evicted according to a predefined policy as soon as the buffer is full. This strategy allows to perform both online and pseudo-offline training by tuning the buffer size, the watermark and by choosing among several selection/eviction policies.
As shown in Fig. 1, both sensitivity analysis and deep surrogate training rely on 3 interacting components:
-
Melissa client: the parallel numerical simulation code turned into a client. Each client sends mid-simulation output to the server each time
melissa_send()(more details here) is called. Clients are independent jobs. -
Melissa server: a parallel executable in charge of computing statistics or training any Neural Network architecture (more details here). The server updates statistics and produces batches upon reception of new data from any one of the connected clients.
-
Melissa Launcher: the front-end Python script in charge of orchestrating the execution of the study (more details here). This module automatically handles large-scale scheduler interactions in
OpenMPIand with common cluster schedulers (e.g.slurmorOAR). Some of the launcher-scheduler interactions include the submission of jobs, monitoring job statuses, and fault-tolerance.
User interface¶
To run an analysis with Melissa, the user needs to:
-
Instrument the simulation code with the Melissa API (3 base calls: init, send and finalize) so it can become a Melissa client (more details here).
-
Configure the analysis (choose how to draw the parameters for each simulation execution, select which statistics to compute or specify the Neural Network architecture, the training algorithm and parameters, more details here).
-
Start the Melissa launcher on the terminal or on the front-end of the supercomputer (quick start tutorial here). Melissa takes care of requesting resources to execute the server and runner, monitor the execution, restarting failing components when necessary.
As of now, Melissa's API is compatible with solvers developed in C, Fortran and Python. However, it can be extended to other languages by following the paradigm inside the API folder.
List of publications¶
- Melissa: Large Scale In Transit Sensitivity Analysis Avoiding Intermediate Files. Théophile Terraz, Alejandro Ribes, Yvan Fournier, Bertrand Iooss, Bruno Raffin. The International Conference for High Performance Computing, Networking, Storage and Analysis (Supercomputing), Nov 2017, Denver, United States. pp.1 - 14. PDF
- The Challenges of In Situ Analysis for Multiple Simulations. Alejandro Ribés, Bruno Raffin. ISAV 2020 – In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization, Nov 2020, Atlanta, United States. pp.1-6. (https://hal.inria.fr/hal-02968789)
-
Alejandro Ribés, Théophile Terraz, Yvan Fournier, Bertrand Iooss, and Bruno Raffin. Unlocking large scale uncertainty quantification with in transit iterative statistics. In Hank Childs, Janine C. Bennett, and Christoph Garth, editors, In Situ Visualization for Computational Science, 113–136. Cham, 2022. Springer International Publishing. ↩